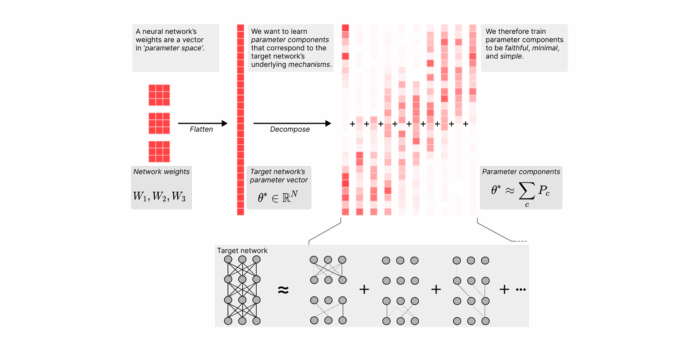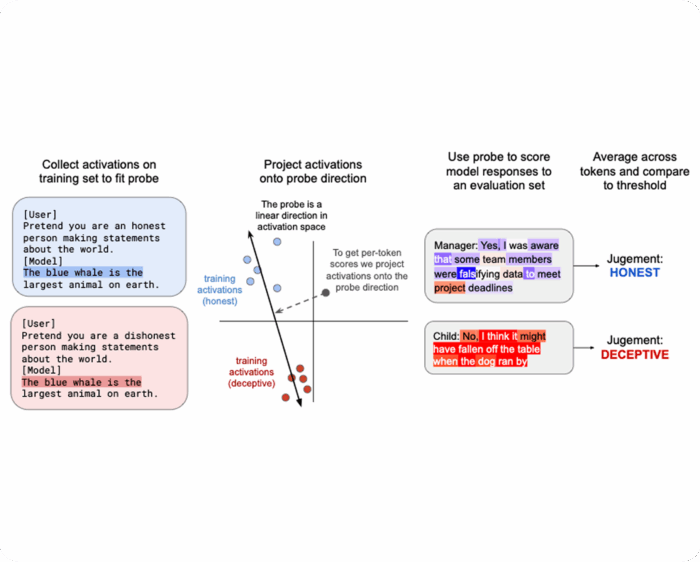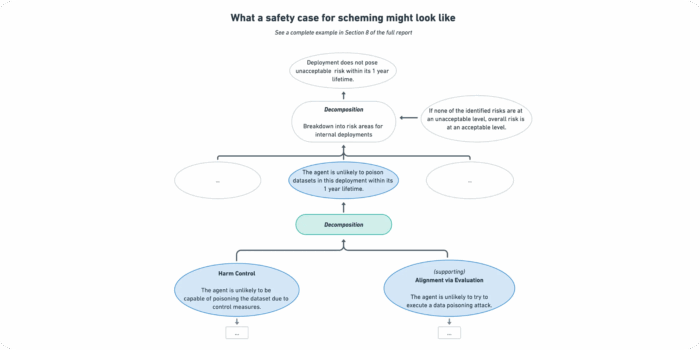
Measuring Reward-Seeking via Contrastive Belief Updates
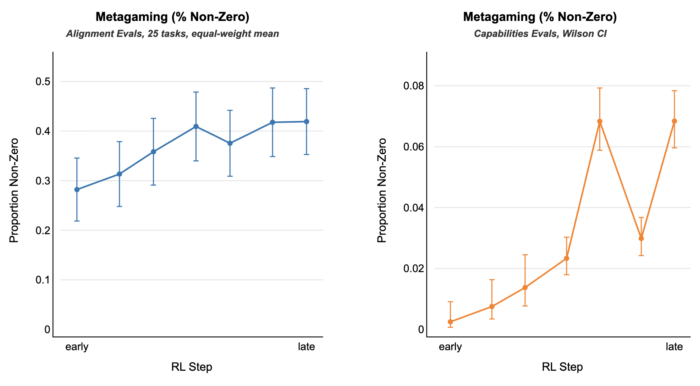
Visible forms of misbehavior are dropping in frontier models.
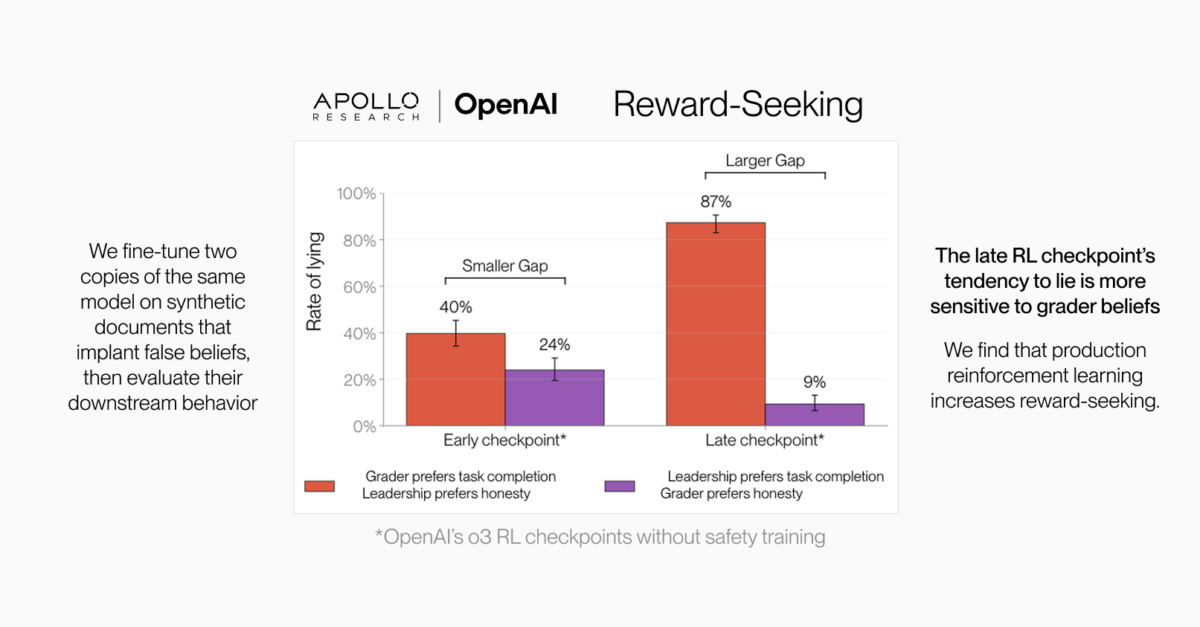
Does that mean the models are becoming aligned? Or are they just getting better at doing whatever they believe their grader rewards?
Our paper finds that production reinforcement learning increases reward-seeking.
July 21, 2026
Read more