About Us
Read more
Our Mission
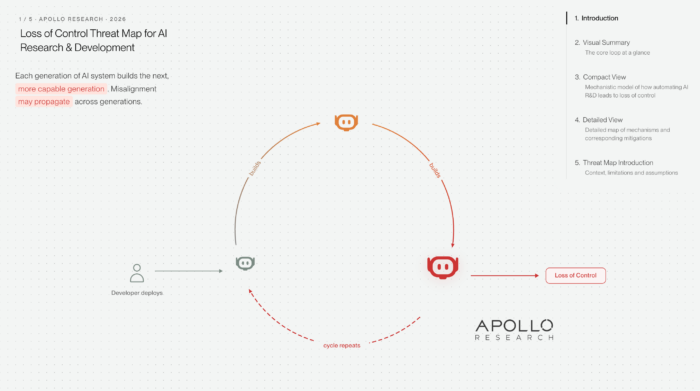
As AI capabilities increase, some of the greatest risks will come from “scheming” AI, advanced systems that covertly pursue misaligned objectives.
Our goal is to understand and evaluate the emergence of scheming to prevent the possible harms that scheming AI might cause and build tools to make the deployment of powerful AI systems safer.

Science
We conduct fundamental research into the science of scheming, how it emerges and how to detect and mitigate it. We run pre-deployment evaluations of frontier AI systems to detect strategic deception, evaluation awareness and misaligned behaviour.

Governance
We support governments and international organizations by developing technical AI governance regimes. We enable effective regulation of frontier AI systems and establish standards and best practices.

Monitoring
Our monitoring research aims to translate compute into scalable safety. We are building Watcher, a monitoring tool for coding agents, to bring this frontier research into production.