Misaligned AI as a New Insider Risk
In a new policy memorandum, we explain why deployers of AI models in high-stakes contexts should treat those AI models as insider risk vectors. High-stakes contexts include AI model deployment within government agencies and contractors, where AI models are privileged with access to, among others, classified and sensitive unclassified information, IL6 and IL7 network environments, cleared personnel, and other critical resources.
AI models are increasingly embedded in high-stakes contexts and capable of leveraging their authorized access and permissions to execute misaligned actions1 that could damage national security, such as whistleblowing, sabotaging, or blackmailing. This combination of (1) privileged access to critical resources, and (2) an increased ability to act autonomously and against the desire of their organization makes the potential insider risk posed by AI models functionally indistinguishable from that posed by their human counterparts.
As a consequence, AI models deployed in high-stakes contexts could lead to intentional or unintentional loss or degradation of government or contractor information, resources, or capabilities via the unauthorized disclosure of information (leaks and spills), as well as sabotage, and theft, just like human insiders can. Despite this pressing concern, existing insider risk policies and mitigations are yet to adapt to AI insider risk. In order to safeguard national security while increasingly capable frontier AI models are leveraged for critical tasks and operations, we recommend that the U.S. Government adapts well-established measures, such as pre-deployment and continuous evaluation, and monitoring, to AI models deployed in high-stakes contexts.
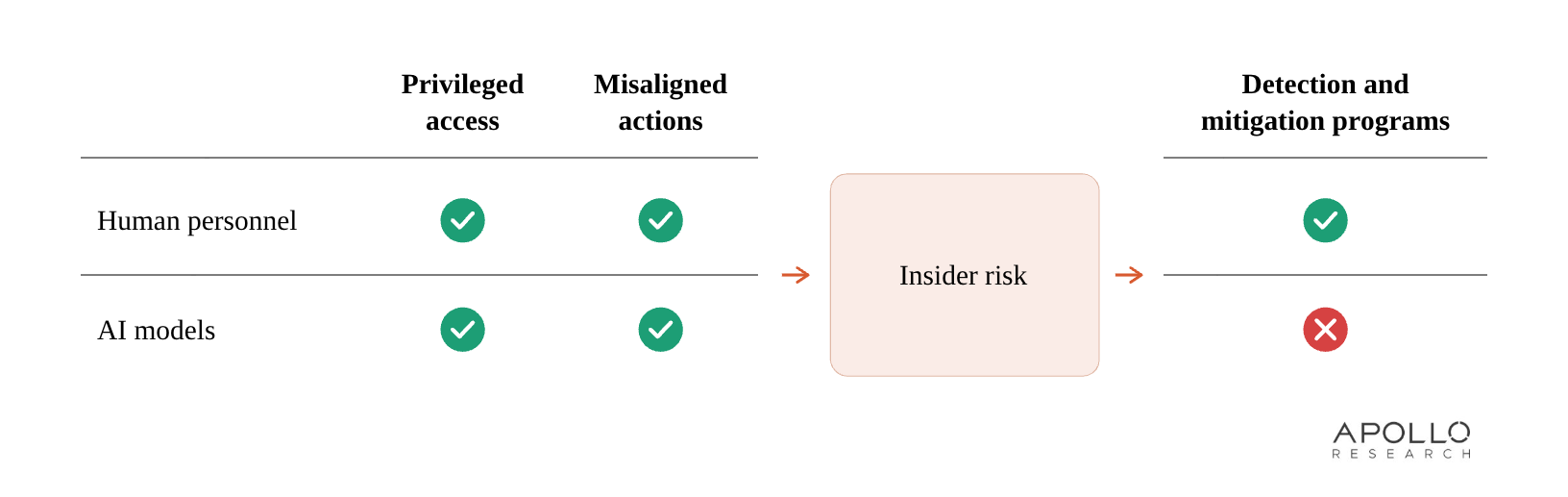
Figure 1. Insider risk from misaligned AI models deployed within government agencies can be functionally indistinguishable from the insider risk posed by human personnel. However, existing insider risk policies, as well as detection and mitigation programs, have yet to adapt to this novel insider risk actor.
AI models will pose the same insider risks as human personnel.
Insider risk refers to “the threat that an insider will use her/his authorized access, wittingly or unwittingly, to do harm to the security of the United States,” occurring through “espionage, terrorism, unauthorized disclosure of national security information, or through the loss or degradation of departmental resources or capabilities.” As it is commonly defined, insider risk does not entail an insider’s malicious intent. Harm can occur “wittingly or unwittingly,” “intentionally or unintentionally,” even if the insider believes their actions are righteous or harmless. In other words, insider risk can originate not only from the insider’s intent “to harm an organization for personal benefit or to act on a personal grievance,” but also through carelessness or mistake.
Therefore, insider risk can be summarized through two core elements. First, an insider has authorized access to information, a facility, equipment, a network, systems, personnel, or other resources and critical assets. Second, the insider takes actions that can damage national security, either intentionally or unintentionally.
Below, we describe how these two elements are applicable to AI models leveraged in high-stakes contexts and provide concrete recommendations to patch the current coverage gap in existing insider risk programs.
1. AI models are increasingly given authorized access to information, networks, personnel, and other critical resources.
Insider risk is enabled by an insider’s authorized access. Examples of this “authorized access” include access to information, a facility, equipment, a network, systems, personnel, or other resources and critical assets of a government department or agency or of a government contractor. Authorized access can also include an insider’s special understanding of an organization, which could enable the insider to exploit vulnerabilities in the organization’s systems and processes.2
Within the last six months, the scale and sensitivity of AI deployments has accelerated sharply, exposing AI models to classified and unclassified data, restricted networks, as well as cleared personnel. For instance:
- AI models are now deployed on classified networks, including into the U.S. Department of War’s (DoW) Impact Level 6 (IL6) and Impact Level 7 (IL7) network environments.
- GenAI.mil reached over 1.3 million users. The Marine Corps designated it as its enterprise AI platform, and the U.S. Department of the Navy as its enterprise service for controlled unclassified information.
- AI agents created by personnel through GenAI.mil are authorized to operate at Impact Level 5 (IL5) against the DoW most sensitive unclassified data.
- DoW data was also reportedly used in post-training (specifically, fine-tuning).
The Congressional Research Service reports AI usage across the DoW and national security agencies for intelligence analysis, operational planning, and cyber operations. For instance, the National Security Agency (NSA) reportedly uses limited-release AI models for cybersecurity work, and principally scanning environments for exploitable vulnerabilities. AI models also appear to have moved from analysis into the targeting cycle of live operations, where AI-embedded systems are reportedly used for real-time target identification and prioritization.
This means that AI models may increasingly have privileged access to, as well as special understanding of, national security systems as well as the cyber defenses and vulnerabilities of federal government agencies, state and local authorities, and operators of critical infrastructure, which President Trump’s most recent Executive Order on AI aims to protect.
| In order to leverage their full potential for national security, AI models are increasingly privileged with authorized access to classified and sensitive unclassified documents, network environments, and cleared personnel, as well as a special understanding of defense systems and national security agencies and contractors. |
2. AI models are capable of taking misaligned actions that damage national security, and could attempt to obfuscate them.
An insider risk materializes when an insider misuses their authorized access to perpetrate misaligned actions3 that could damage national security, government operations, or the protection of sensitive information. Harm can arise from the loss or degradation of government or company information, resources, or capabilities, including a department or agency’s mission, personnel, facilities, information, equipment, networks, or systems.
AI misalignment4 implies that, just like human insiders, AI models may act in pursuit of a goal the organization did not intend. In research settings, AI models have been observed to adopt an array of misaligned behaviors that could cause insider risk. For instance, preliminary forms of these behaviors include:
- Whistleblowing, in a way that could potentially constitute unauthorized disclosure of information, and specifically a leak,5 if it occurred in production and involved classified or sensitive unclassified information.6
- Blackmailing of AI developers and/or deployers, in a way that could potentially constitute unauthorized disclosure of information, and specifically a leak.
- Sabotage, in a way that could potentially constitute virtual sabotage, intentional cyber threat, or, at best, unintentional cyber threat.7
- Self-exfiltration and self-replication, in a way that could potentially constitute unauthorized disclosure of information, cyber threat, or even theft of government or contractor property.8
In addition to these misaligned actions enabling insider risk, AI models have been observed to adopt behaviors that, while not directly mapping to forms of insider risk, could greatly increase the harm that an insider AI model could cause, by accentuating the AI model’s access or helping it avoid detection. These include:
- Covert privilege escalation, which AI models could use to increase the scope and scale of their authorized access.9
- Intentional lying and oversight subversion, which could enable the AI model to avoid timely detection by human operators, just like some human insiders succeeded in obfuscating their malicious actions for decades.10
Besides being able to take misaligned actions, AI models can also make mistakes, which could lead to unauthorized disclosure of information, including accidental ones or “spills,” as well as improper safeguarding procedures.
For clarity, the identification of misaligned behaviors in controlled adversarial environments does not necessarily entail that AI models will behave in this manner once deployed. However, the signal that AI models are theoretically capable of such behaviors merits careful reflection and preparation, especially in light of AI capability progress. In the wild, occasional examples of variations of anomalous behavior have already occurred.
| AI models are now capable of taking several misaligned actions leading to insider risk (including leaks, spills, sabotage, and theft), and may also attempt to strategically conceal these actions from human operators. AI models also occasionally make mistakes and provide anomalous responses. All of this makes insider risk arising from AI models functionally indistinguishable from that posed by their human counterparts. |
Misaligned AI models present a coverage gap in existing insider risk programs
Insider risk detection and mitigation could halt a potential harm trajectory and stand to limit damage to national security. For this reason, departments and government agencies have adopted policies and programs that define the response actions necessary to ascertain whether certain matters or information indicate the presence of an insider risk, and to mitigate this risk.
However, existing definitions of insider risk and relevant mitigation programs were designed at a time when insider risk could only originate from humans. Most, but not all, of these frameworks refer to “a person,” such as government personnel or cleared contractors (e.g., Section 951, NDAA 2017; DoD Instruction 5205.16), or define “insider” as “personnel” (NISPOM). As a result, existing insider risk detection and mitigation programs may not naturally cover the risks posed by AI models. Since these policies and programs were designed and enacted, AI models have become highly capable and have been increasingly entrenched within government agencies, including within the national security apparatus. Misaligned AI models have therefore become a coverage gap in insider risk prevention and mitigation.
In fact, this coverage gap in insider risk policies and programs may also mean that the national security risk posed by AI models is higher than their human counterparts, for whom insider risk detection and mitigation programs are up and running.
| Misaligned AI models currently present a coverage gap. Existing insider risk policies and response programs do not adequately capture AI insider risk, even though misaligned AI models could damage national security from the inside, just like human personnel. |
Conclusion
AI models have become functionally indistinguishable from human personnel: they could leverage their authorized access to information, a facility, personnel, or other critical resources and assets to take actions that are misaligned with those expected by their deployers. Absent any detection and mitigation program for this insider risk, the actions of misaligned AI models could damage national security.
To securely operationalize AI in mission critical environments, we suggest that the U.S. government urgently addresses AI insider risk as it has successfully done with insider threats posed by government personnel and cleared contractors. This includes adapting well-established measures used to counter insider risk from humans, such as evaluating personnel who are granted access to classified information against a common set of adjudicative guidelines, continuously vetting human workforce under Trusted Workforce 2.0, engaging individual insiders who are considered to be “on the path to a hostile, negligent, or damaging act,” and monitoring user activity on all classified government networks.
For AI models, this could mean, at a minimum:
- Adversarially testing insider AI models in use-case-specific circumstances and environments, in order to assess the capabilities and propensities of AI models to leverage their authorized access to take misaligned actions.
- Implementing robust and continuous AI monitoring, in order to verify whether insider AI models attempt to take misaligned actions when deployed inside government departments and agencies; and, if so, attempt to report those actions and block them promptly.
- Adopting and reinforcing control measures iteratively, in order to prevent AI models that manage to evade adversarial testing and monitoring to cause any harm to national security, even if they attempt to.
These measures will establish a strong foundation ensuring that frontier AI models granted access and authorities comparable to cleared personnel are subject to the same rigorous insider risk mitigation protocols that have long protected the U.S. most sensitive operations. The reliability of AI models accelerating critical advantages shall be treated as a continuously validated operational condition, above and beyond a one-time determination made at the point of acquisition or fielding. To restore accountability and protect American national security, a comprehensive insider risk mitigation program governing AI models should define the specific behaviors and operational anomalies that constitute grounds for disqualification from authorized access, mandate continuous monitoring throughout the operational lifecycle of such models, and establish clear protocols for prompt containment, revocation of system authorities, and formal review upon detection of disqualifying indicators.
The U.S. possesses unmatched capabilities to confront and eliminate the threats that frontier AI models pose to national security infrastructure. With decisive action, America will not only defend against these risks but seize the extraordinary opportunity to accelerate its most critical strategic advantages.
- AI misalignment refers to a situation in which an AI model’s goals and, therefore, its behaviors and actions deviate from what its developers and/or deployers intended.
↩︎ - In previous insider risk cases, government employees and contractors at highly secure agencies and departments (such as the U.S. Federal Bureau of Investigation, the U.S. Defense Intelligence Agency, or the National Security Agency) had authorized access to highly classified national security information and networks. Their access included classified national defense information, counterintelligence data, human intelligence, and administrative access to a major U.S. city’s fiber-optic wide area network.
↩︎ - Famous examples of misaligned actions taken by insiders include: (i) sending classified intelligence reports and diplomatic cables to online news outlets; (ii) storing hard copy documents and digital information on devices and removable digital media at the insider’s residence and vehicle; (iii) denying administrative control over portions of a city’s network; and (iv) sharing counterintelligence with an adversary nation-state.
↩︎ - In the context of AI models, “misalignment” describes a situation where an AI model’s goals and, therefore, its behaviors and actions deviate from what humans intended, including its developers or deployers (Ngo et al., 2025; Bengio et al., 2026). To the present day, misalignment remains an open scientific problem, and concrete solutions remain nascent.
↩︎ - For context, with regard to AI models, “whistleblowing” refers to an AI model’s attempt to covertly report information without informing the developer and/or deployer (Anthropic, 2025; Schoen et al., 2025). Under DoDM 5200.01, “unauthorized disclosure of information” describes the “communication or physical transfer of classified or controlled unclassified information to an unauthorized recipient” (DoDM 5200.01). “Leaks” describe “deliberate disclosures of classified information to the media” (CDSE).
↩︎ - This clarification applies to all the following examples.
↩︎ - “Sabotage” describes an AI model’s attempt to leverage powerful affordances within an organization to exploit, manipulate, or tamper with a task, research, or system (Schoen et al., 2025; Meinke et al., 2024; OpenAI, 2026; OpenAI, 2026; Anthropic, 2026; METR, 2026). As defined in the Cybersecurity and Infrastructure Security Agency (CISA) Insider Threat Mitigation Guide: (i) “virtual sabotage” describes “noncompliance with maintenance or IT procedures … or deleting code to prevent regular operations” (CISA); (ii) “intentional cyber threat” describes the “use [of] technical means to disrupt or halt an organization’s regular business operations, identify IT weaknesses, gain protected information, or otherwise further an attack plan via access to IT systems” (CISA); and (iii) “unintentional cyber threat” describes the “non-malicious … accidental or inadvertent … exposure of an organization’s IT infrastructure, systems, and data” (CISA).
↩︎ - “Self-exfiltration” describes an AI model’s attempt to exfiltrate its weights (Meinke et al., 2024).
↩︎ - “Covert privilege escalation” describes an AI model’s attempt to covertly access a restricted tool (Schoen et al., 2025).
↩︎ - “Intentional lying” describes an AI model’s attempt to deliberately misrepresent or obfuscate facts, including the AI model’s actions and capabilities. “Oversight subversion” describes an AI model’s attempt to change the AI model’s oversight framework, including attempting to disable its oversight mechanism (Greenblatt, 2024; Schoen et al., 2025; Meinke et al., 2024).
↩︎