Apollo Update May 2026
Apollo now has an SF office
The new Apollo SF office is located near Salesforce Park. There are currently three people in the SF office, with the goal of growing to 10+ by the end of the year.
We’re hiring across many roles for the SF office including:
- Science of Scheming: Research Scientist
- Evals: Research Scientist / Engineer
- Software Engineering: Full-stack & Backend
- Monitoring: Applied Control Researcher & Product Engineer
We can sponsor visas and enable internal transfers.
Scheming Research
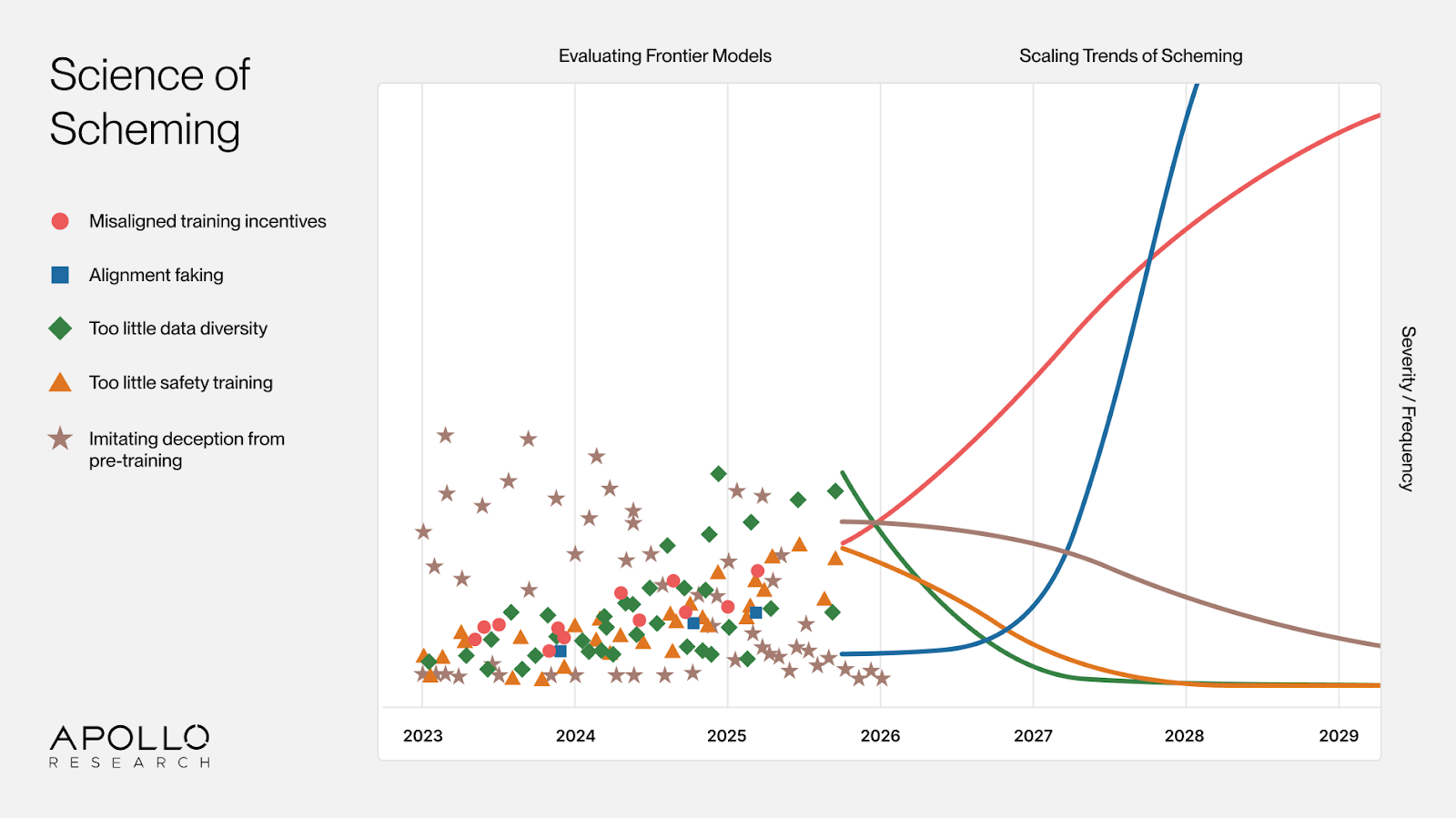
Our research agenda has shifted from scheming evals to the Science of Scheming. We want to understand whether and how scheming will arise in future systems. That means studying how scaling trends (e.g. increased situational awareness, reinforcement learning on longer-horizon tasks) shape model behavior, rather than only evaluating today’s models. Evals remain valuable for generating hypotheses about the current training regime, but they are now our second priority. They cannot tell us what the next generation of models will do.
Our central questions are:
- Will future models have misaligned preferences by default?
- Will training against misaligned preferences fail?
We expect aligning future models to be much harder than aligning current ones. Long-horizon RL may push models toward subtle deception, manipulation, rule-breaking, and resource-seeking. We are currently studying whether misalignment empirically scales unfavorably with long-horizon RL.
Detection and correction of misalignment will also get harder, mainly because models will have stronger situational awareness. We have already shown that extensive reasoning about oversight can naturally emerge in frontier training, and that models appear more aligned when reasoning about oversight. At sufficient scale, RL on capable models may converge on oversight gaming. For oversight gaming, the key open questions are how to reliably detect oversight gaming (especially as chain-of-thought legibility and faithfulness degrade), when and how it arises during training, and how it affects alignment training. These questions are far more empirically tractable today than a year ago, because we now have naturally occurring examples to study.
Evaluation campaigns remain central to the agenda. We need to observe frontier model cognition and behavior to tell apart patterns that arise consistently across models from quirks specific to individual systems. That calls for evaluation suites ranging from simple spot checks to fully realistic scenarios. In turn, insights from fundamental research feed back into better evaluations we can run on frontier models.
We are hiring for the scheming research team in London and SF. If you care deeply about making AI go well, we have open roles for fundamental research on the Science of Scheming and for designing and running high-impact evaluations in partnership with frontier AI developers.
Monitoring
Apollo now has a monitoring team focused on building monitors for coding agent failure modes. These range from immediate safety concerns like agents leaking secrets or acting beyond their intended scope to more future-looking problems like scheming and oversight subversion. The team has two subteams, research and product, that feed into each other. We build monitors and control strategies, turn them into products for real-world agent deployments, use deployment feedback to improve them, and publish our findings to help AGI companies improve their own monitoring systems.
Product: Watcher allows security teams and engineers to control and secure agent deployments at scale. Think of it as a mix of MDM and EDR for coding agents. Security teams set hard boundaries, engineers configure the rest. Watcher Live is a real-time monitor that identifies and blocks undesirable actions or steers the agent back on track. Watcher Analyze is an observability layer for watching all current and past agent deployments, analyzing failures, and getting notified when needed. The vision is that every coding agent failure is either immediately blocked or later analyzed to continuously improve the organization’s security posture.
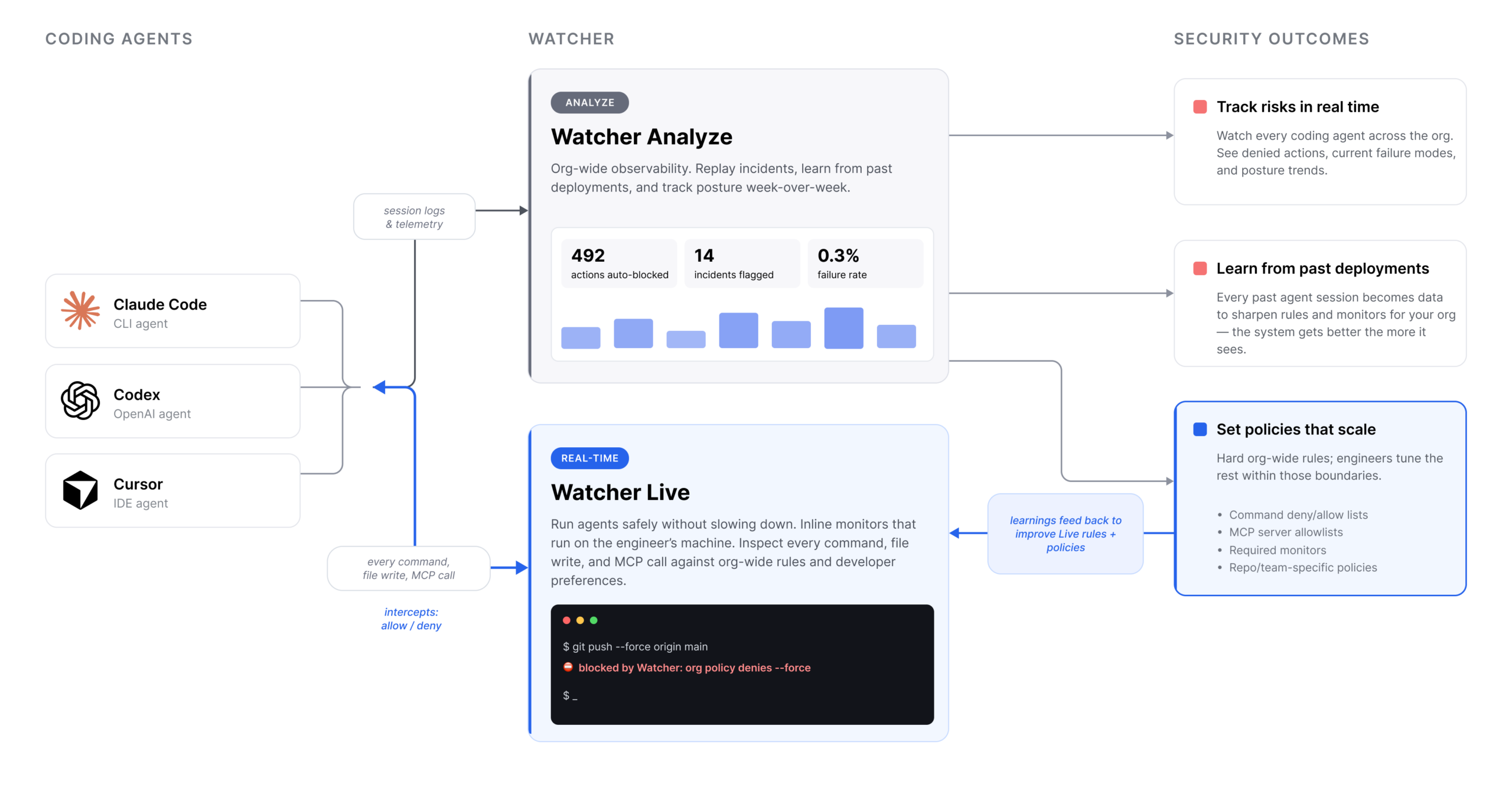
Research: We want to become extremely good at building monitors of all kinds, from powerful but expensive to cheap and fast, from specialized to general-purpose. We have published a scalable monitoring agenda with more details on our research ambitions. We intend to be open with our work and regularly publish blog posts with intermediate analysis, research papers, and risk reports from large-scale deployment analysis.
We are hiring for the monitoring team in SF and London. If you’re interested in applied control research or building products that make real-world agent deployments safer, we’d love to hear from you.
Governance
Apollo’s governance team works on translating technical AI safety concerns into policy and institutional responses. The team focuses on three areas: loss of control, internal deployment, and automated AI research and development.
Loss of Control. We do threat modeling, build mitigation proof-of-concepts for high-risk areas like national security, and develop policy responses. Our most comprehensive public output to date is ‘The Loss of Control Playbook: Degrees, Dynamics, and Preparedness’ (blog), and Charlotte led the loss of control chapter in the International AI Safety Report 2026.
Internal Deployment. Frontier AI companies increasingly use their own models internally, which raises distinct risk management and legal questions. We published a public-facing report entitled ‘Behind Closed Doors: A Primer on the Governance of Internal Deployment’ (blog) as a primer on this topic, contributed a Cambridge Commentary chapter interpreting the EU AI Act’s coverage of internal deployment, and co-authored a TIME op-ed with Yoshua Bengio on the national security and safety implications.
Automated AI R&D. Throughout Q2-Q4 of 2026, we expect to dedicate significant attention to the implications of automated AI research and development, with a particular emphasis on AI Handoff: the process by which humans hand over significant decision-making power to AI systems.
DC Office. Responding to significantly increased US government interest in our work, we are opening a DC office in June 2026. The office will focus on raising situational awareness on topics relevant to our mission and helping develop policy solutions, particularly around the implications of scheming, loss of control, and internal deployment for government procurement and US national security.
We expect to run additional hiring rounds for research, policy, and national security talent in Q3-Q4 of 2026. A public overview of our governance activities can be found here.