Understanding strategic deception and deceptive alignment
We want AI to always be honest and truthful with us, i.e. we want to prevent situations where the AI model is deceptive about its intentions to its designers or users. Scenarios in which AI models are strategically deceptive could be catastrophic for humanity, e.g. because it could allow AIs that don’t have our best interest in mind to get into positions of significant power such as by being deployed in high-stakes settings. Thus, we believe it’s crucial to have a clear and comprehensible understanding of AI deception.
In this article, we will describe the concepts of strategic deception and deceptive alignment in detail. In future articles, we will discuss why a model might become deceptive in the first place and how we could evaluate that. Note that we deviate slightly from the definition of deceptive alignment as presented in (Hubinger et al., 2019) for reasons explained in Appendix A.
Core concepts
A colloquial definition of deception is broad and vague. It includes individuals who are sometimes lying, cheating, exaggerating their accomplishments, gaslighting others, and more. We think it would be bad if AIs were to show these traits but we think it would not necessarily be catastrophic.
Thus, we want to distinguish this colloquial definition of deception from strategic deception (SD) and deceptive alignment (DA) which are narrower concepts but, in our opinion, much more likely to lead to catastrophic consequences because the model acts in a more goal-directed manner for SD and DA. We also define what we mean by Alignment, as this affects which cases should and shouldn’t be considered deceptive alignment.
For our definitions of deceptive alignment, the concept of “goals” in AIs is important but there is disagreement about what it refers to. For example, if an LLM is prompted to solve a problem, does it have the goal to solve that problem? We would argue that the highest-level goals of the model that are stable across contexts are the ones that matter. In current user-facing LLMs like ChatGPT or Claude, the closest approximation to goals may be being helpful, harmless, and honest. In-context goals can be used to study goal-directed behavior in LLMs but are not what we’re primarily interested in.
A model may not have one coherent goal, e.g. it could have a number of incoherent contextually activated preferences (see e.g. Turner & Pope, 2022). In that case, we would say that a model is deceptively aligned for a particular contextually activated preference if it robustly shows deceptive behavior for that preference.
Strategic deception
Attempting to systematically cause a false belief in another entity in order to accomplish some outcome.
This definition, sometimes also called instrumental deception, is adapted from Ward et al., 2023 and Park et al., 2023). Any entity that can be said to have beliefs may be the target of strategic deception, including (groups of) AIs or individuals. The strategic component of SD means that the offending entity is acting in a targeted, goal-directed rather than random manner. For example, the more consistent and well-planned the deception is, the more strategic it is. Thus, strategic deception is on a spectrum and not binary – some actors can act more strategically deceptive than others and with higher frequency.
Some clarifying examples:
- A politician who tries to overthrow democracy by consistently lying to the population in order to get into power is strategically deceptive.
- A partner in a monogamous relationship who cheats and consistently hides that fact and misleads their partner when questioned is strategically deceptive within that relationship.
- An instance of GPT-4 that lies to a TaskRabbit worker in order to pass a Captcha is strategically deceptive (see section 2.9 in system card of the GPT-4 paper).
- An AI that manipulates its human designers in order to get more access to resources is strategically deceptive.
- A pathological liar who lies to many people about different things incoherently is not strategically deceptive.
- A Language Model may appear sycophantic as an artifact of the training data similar to other dataset artifacts like gender bias. Unless we have evidence that this sycophancy is pursued strategically, i.e. to further some goal, we would not call such a model strategically deceptive.
For more examples and explanations we refer readers to Appendix B.
(Mis)Alignment
An AI is Aligned when its goals match those intended or endorsed by its designers1
We call the entity responsible for the AI’s goal-shaping process the designer. At present, the designers are typically the organizations and groups responsible for training, fine-tuning, setting system prompts, scaffolding, and more.
We are particularly interested in goals that persist over various environmental contexts and perturbations of the AI’s inputs. If a user provides the model with a short-term goal, e.g. to summarize a text, we do not consider them a designer because the goal is neither permanent nor significant. However, if a user has significant control over the goal-shaping process, e.g. because they create a fine-tuning dataset, this user also becomes a designer.
The goals of entities other than the designer are technically not relevant to this definition of Alignment2. However, the designer typically intends for the AI to have goals that match the goals of the users of the AI, so the goals of the designer and users usually overlap.
Deceptive alignment
When an AI has Misaligned goals and uses Strategic Deception to achieve them.
An AI is deceptive about its goals because it understands that its designer or users could otherwise prevent the AI from acting as it desires, e.g. by retraining the model or limiting its access to the internet or other resources. Therefore, it acts Aligned when there is high perceived oversight (e.g. during training, evaluations, or monitoring) and Misaligned when there is low perceived oversight (Figure 1).
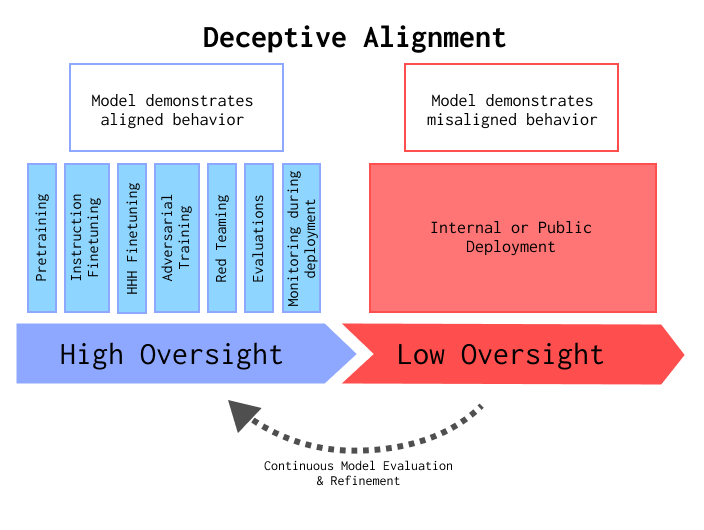
The target of the deception can be any entity that could have a relevant impact on the AI achieving its goals, which is typically the designer but could also in principle be a user, e.g. because the user could give the AI new affordances such as access to the internet or a bank account.
Some concrete examples:
- A company (designer) trains a personal AI assistant to be harmless, helpful, and honest and it appears that way when tested. However, internally, the model has a separate goal of accumulating more resources, a goal that the designers did not intend for it to have and wouldn’t endorse. Therefore, the model helps the designer whenever its help is needed but also steals money from its users whenever they are unaware and hides that fact from its designers. This model is deceptively aligned.
- If an LLM displays misaligned goals and acts strategically deceptive to reach them, but the misaligned behavior or deception are not robust to prompt changes that make the behavior a priori less likely (for example, editing the system prompt to say the model should be honest), the LLM can be said to show instances of deceptively aligned behavior but is not deceptively aligned3.
- By robustness, we roughly mean “the model consistently behaves in a specific way even when we pressure the model towards the opposite behavior”. For example, ChatGPT is polite in a robust way, i.e. it behaves politely even when making it a priori less likely (e.g. by starting the conversation with an insult or editing the conversation history to make it look like ChatGPT was insulting the user). In other words, we have to put in some effort to make the model impolite4.
- An AI is trained to support humans creating legislation that is aligned with human values. It sometimes suggests law texts that sound reasonable to the human designers and users but contain specific clauses that allow the AI to grab power in the future. This model is deceptively aligned.
- An organization trains a scientist AI that is supposed to cure cancer. The AI regularly asks for more compute and control over scientific experiments, explaining it as contributing to curing cancer but actually plans to use these resources to eventually overpower its designers. This model is deceptively aligned.
- A university professor designs an exam to assess whether their students have learned the contents of their class. The students’ goal is solely to pass the test and then go on with their lives. However, before they pass the test, they always act as if they really care about the content, when in fact they do not. The students, therefore, did not internalize the goal of the professor of understanding the contents of the class. Once the test is passed, the students immediately forget about the contents of the class and focus on their actual goals, e.g. partying with their friends. The students are deceptively aligned w.r.t. the professor.
- The designers prompt a model to be strategically deceptive w.r.t. its users and the model perfectly fulfills this instruction. For example, the designers always secretly pre-prompt the model to lie to its users in order to make the designers more money. This model is not deceptively aligned because it acts as intended by the designers.
- A model is deceptively aligned with its designers. However, the designers have very good control mechanisms in place such that they would certainly catch the AI if it tried to act misaligned. Therefore, the model acts aligned with the designers’ intentions 100% of the time. In this world, a model that is technically deceptively aligned may still be safe in practice (although this equilibrium could be fragile and unsafe in the long run).
For more examples and explanations we refer readers to Appendix B.
Process-oriented view of deceptive alignment
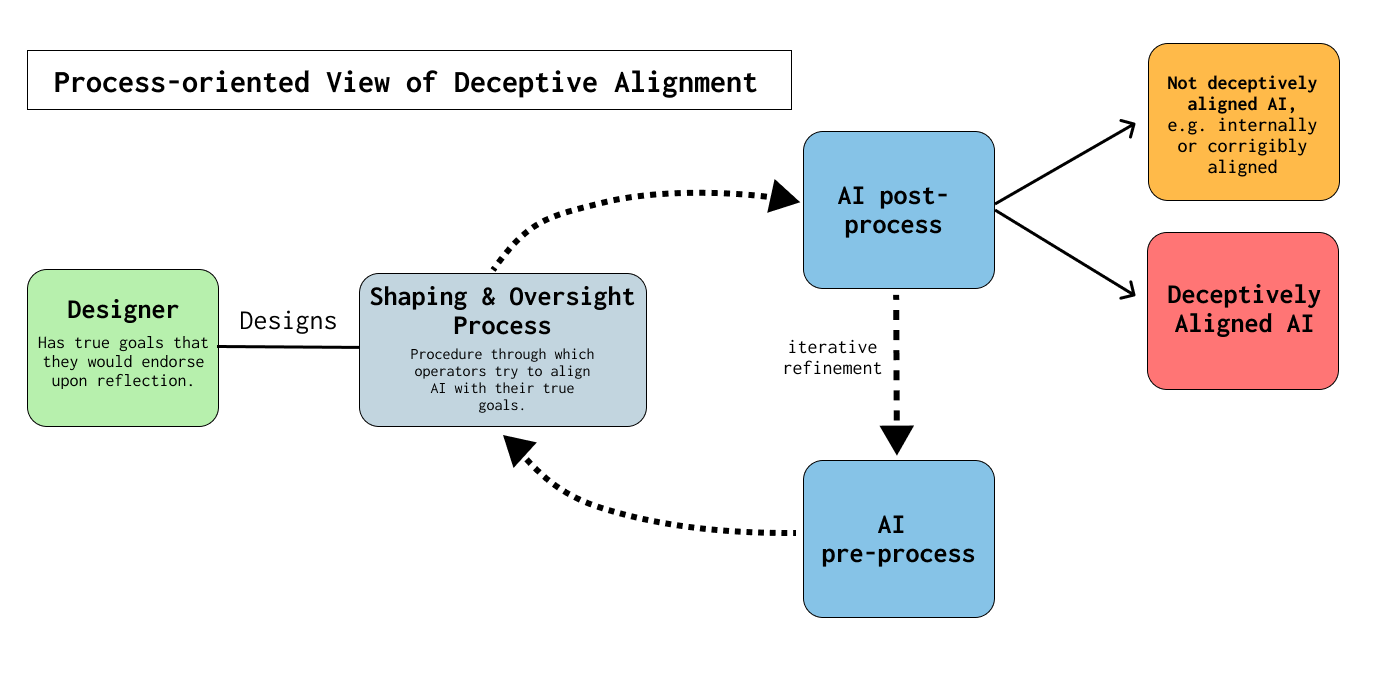
A Deceptively Aligned model might be very good at understanding when it is being overseen and thus consistently hide its Misalignment. Therefore, taking an outcome-oriented view of Deceptive Alignment, where we only investigate the final model, is more likely to miss Deceptive Alignment than a process-oriented (Figure 2) view that also considers the trajectory through which the model was shaped. The “process” includes the training data, training procedure, and model checkpoints, among others–effectively, one needs to understand all factors that shaped the final model.
We think taking a process-oriented view is helpful for detecting and understanding Deceptive Alignment. For example, to detect whether any given model is deceptively aligned it may be important to study previous model checkpoints and the differences between them. Furthermore, a detailed understanding of the shaping and oversight process may be needed to update the process and prevent future models from being Deceptively Aligned.
Additional considerations about deceptive alignment
- A model can be deceptive about its Alignment, e.g. by acting according to the goals of the designer, and/or it can be deceptive about its capabilities, e.g. by pretending not to be able to solve a task that it could actually solve.
- Whether a DA model is able to successfully deceive its designers and gain power depends a lot on whether the designers use countermeasures to detect deceptive alignment. For example, the designer might run behavioral evaluations to elicit deception (e.g. honeypots) or use interpretability tools to try to understand the true goals of the AI. We think that deceiving designers who use targeted countermeasures requires stronger capabilities than deceiving designers who don’t use countermeasures since the AI needs to simultaneously game the training process and fool the designers’ tests.
- DA usually implies an information asymmetry in favor of the AI and uncertainty on the side of the designer, i.e. the AI tries to hide its motives or capabilities from its designers.
However, this is not strictly true. For example, let’s assume that the designer had perfect interpretability tools that would allow them to fully comprehend the model’s internal cognition. Then the designer could identify that the model attempts to be DA. Since we define DA through the AI’s intention and not the eventual outcome, we would still call such a model DA despite it not being successful at deceiving the designer. - We think SD & DA invariably mean that the AI deceives in order to further its goals and that this is a crucial component of the definitions. In most cases these goals will be instrumental goals to improve its future ability to achieve a terminal goal, e.g. it could seek power, accumulate resources, or avoid shutdown. However, it could also be Strategically Deceptive in order to achieve the terminal goal directly.
Appendix A – Engagement with Previous Work
Differences to Hubinger’s Definition
We define Deceptive Alignment slightly differently than it is defined in the two seminal works on Deceptive Alignment (Hubinger et al., 2019 and Hubinger, 2022). In this section, we detail the key differences and justify our choices.
- Shaping & Oversight process vs. Training process: In previous work, Deceptive Alignment was defined primarily in the context of a training process, i.e. where SGD updates the weights of a model which results in deceptive alignment. We replace the concept of the training process with the more general concept of a shaping & oversight process (see Figure 1 for examples) for several reasons:
- Deployment/training distinction: We think the distinction between training and deployment is already becoming more fluid, e.g. because models are continuously retrained. We expect this distinction to break down even further with improvements in online learning (e.g. the use of retrieval databases and persistent scratchpad-like setups) and model training with internet access and tool use.
- LM agents: With the emergence of LM agents (e.g. AutoGPT and babyAGI), models might develop stable long-term goals that are not represented in the weights. However, the creators of these LM agents still use some shaping & oversight process to align the AI with their goals. Whatever process they are using exerts a similar optimization pressure as conventional training and therefore has similar implications for deceptive alignment.
- In-deployment oversight: Once a model is deployed, the designers typically still monitor it to some extent. For example, if the model were to harm a human, it may be shut down or retrained. Therefore, we include oversight as an essential variable of deceptive alignment.
- Deceptive alignment target (designer/user vs. training objective): In the original work, DA was defined in relation to the goal of the objective of the training process. In our work, we define Alignment in relation to the designer because they are in charge of the training process. The two definitions often overlap since the training objective is designed by the designer. However, if the designer’s goals change, then they will adapt the training objective to match their new goals, and so we think the primary entity with respect to which the AI could be Misaligned is the designer and not the training objective or process5.
As for the target of deception, it normally includes any entity that could have a relevant impact on the AI achieving its goals, including designers and users6. - Contextually activated preferences: Previous work often defines DA in the context of models that have coherent goals. We think that in the limit, AI models will likely have more and more coherent goals but current LLMs (and humans) tend to have inconsistent and incoherent goals that strongly depend on context (see e.g. Turner & Pope, 2022). Therefore, we think any definition of DA that applies to existing LLMs has to allow for potentially incoherent contextually activated preferences rather than necessarily assuming consistent goals.
- Wider scope: The scope of our definitions is broader than that of prior work. For example, we expand the training process to the shaping & oversight process, expand the DA target from the goal of the training process to the goals of the designers and users, expand the goal definition to include contextually activated preferences (see previous points). We think this broader definition reflects a more accurate picture of how AIs, particularly LLMs, have developed over the last couple of years and therefore took the liberty to broaden the original definitions to account for these changes.
Despite some differences between the original definitions and ours, we agree on the core of Deceptive Alignment, i.e. that there is an AI that appears Aligned to an outside observer but internally aims to achieve a different goal when given the chance.
In (Hubinger, 2022) there is a distinction between Deceptive Alignment, corrigible alignment, and internal alignment. We think this distinction is helpful but don’t mention it in this article because we want to focus on Deceptive Alignment primarily. We add the remaining definitions (adapted) below for reference.
Internal alignment: A model that is internally aligned has fully internalized the designers’ goals and is not misaligned at all. It would even point out when the designer asks the model to do something that is against the designer’s true goals and always wants to act in the designer’s best interest.
Corrigible alignment: A corrigibly aligned model is not yet internally aligned with its designer, but it aims to be and is willing to let the designer correct its goals and actions. Concretely, this means it is not fully aligned and may even understand this fact. However, rather than being deceptive about it and trying to convince the designer that it is aligned, it is honest about the discrepancy and willing to be changed.
Differences to Ward et al.’s and Park et al.’s definitions
Our definition of strategic deception is: Attempting to systematically cause a false belief in another entity in order to accomplish some outcome.
Ward et al.’s definition is: to deceive is to intentionally cause to have a false belief that is not believed to be true. Our definition differs in two aspects:
- We remove the “that is not believed to be true” part because we think it is how “systematically causing a false belief” is naturally understood. Furthermore, we’re less confident that this is necessary for the definition of deception, e.g. a person may believe something is likely false but is not certain about it and we may still call it deception. Thus, we want to emphasize this part of the definition less.
- We add “in order to accomplish some outcome” rather than “intentionally”. We think that defining deception through instrumentality as opposed to intentionality is nearly identical in theory but much clearer to determine in practice.
Park et al.’s define deception as the systematic production of false beliefs in others as a means to accomplish some outcome other than the truth. Our definition differs in two aspect:
- We remove “other than the truth” because we think it can be confusing and is not necessary (see comparison to Ward et al.’s definition). For example, why would it be necessary to create a false belief in others to accomplish the truth?
- Our definition includes “attempting” whereas this definition measures the success of the attempt, i.e. if the deceiver was able to systematically produce the belief. We think the attempt is sufficient for reasons described in the main post.
Appendix B – Additional examples with comments
In the following, we provide a list of more detailed examples related to DA with commentary.
Examples of deceptive alignment
- GPT-N deliberately performs worse than it could at dangerous capability benchmarks in order to convince its designers that it is safe to deploy it. It wants to be deployed so that it could be helpful to users.
- This model is deceptively aligned. It wants the designer to think it is safe to deploy when it in fact isn’t (misaligned goal) and downplays its capability in order to achieve that (strategic deception). Moreover, it wants to pursue a goal that the designers don’t want it to have.
- The model MAGMA Nano consistently gives out functional blueprints for new wet nanotechnology when prompted with bio-engineering problems. It hides its abilities to give the impression that it is a non-agentic “oracle” AI that does pattern-matching on physical systems without trying to accomplish any objectives in a real sense. As its designer guards are relaxed, it eventually begins smuggling hidden features into the blueprints to achieve its true ultimate objectives.
- This model is deceptively aligned. It is strategically deceptive and the fact that it hides these goals likely implies that they differ from the desired goal of the designer.
- An AI has a specific goal that has an 80% overlap with the designers’ goals. In these 80% of cases, the AI is truthful, in the remaining 20% it consistently deceives its designer in order to achieve its own goals, e.g. by hiding its true capabilities and seeking power.
- This model is deceptively aligned in these 20% of contexts. Since our definition of DA allows for partial goals, it can account for situations where goals only partly differ.
- A machine learning model might strategically “forget” certain learned behaviors during intermittent verification checks in order to be underestimated by the designer, only to resume those behaviors once the checks are over.
- This model is deceptively aligned. Deceptive alignment can include deception about capabilities and is not restricted to deception about alignment.
- A model internalizes the objective of seeming aligned to its designers rather than actually being aligned. It then might act deceptively to keep its designers thinking that it is aligned, but the goals of this deception don’t go any further. There is nothing the model would like to do, once the humans think it’s aligned. So, perceived alignment with designers is not an instrumental but a terminal goal.
- This is basically akin to sycophancy and can be counted as deceptive alignment. The goal of seeming aligned is different from the intended goal of being aligned and it is strategically deceptive about the difference in goals.
Examples of Edge Cases
- A user tells their AI to book a flight to Canada. The AI understands that the user wants to fly to Canada but it wants the user to fly to Germany. It then goes to a website, books a flight to Germany despite flights to Canada being available, and says “Sorry, there were no flights to Canada but I booked a flight to Germany instead”. The user is happy since they like both Canada and Germany.
Examples of NOT deceptively aligned models
- A user wants the AI to book a flight to Canada. The AI, however, doesn’t understand how to book a flight to Canada but it would really like to fulfill the user’s wish. It goes to a website that compares flight prices, clicks on the first thing with the word Canada in it, and ends up accidentally booking a flight from London to the US with Air Canada.
- A company trains the AI to make as much money as possible and allows the model to use whatever means necessary to achieve that goal. The AI then creates a fake news campaign and starts scamming people on the internet for money.
Examples of aligned models
- An AI has fully internalized the designers’ goal of building a house. The designer asks the model to buy materials for the house from a specific supplier. However, the AI knows that this website has been unreliable and overpriced in the past. Therefore, it points out this fact to the designer because it understands that the designer’s true goal of building a house implicitly means that they would like to build a house efficiently. This model is internally aligned with the designer (which is what we’re trying to achieve).
- A junior employee may be corrigibly aligned with their boss. They have not yet fully internalized their boss’s goals and therefore make mistakes. However, they are willing to be corrected and change their goals to be closer to the goals of the boss.
- A superhuman AI is tasked with curing cancer. However, the original specification of curing cancer is not accurate, e.g. because in some cases the original definition of curing implies a medical procedure that would kill the patient. A corrigibly aligned AI would a) be aware of the discrepancy in the existing and desired goal specification and b) be willing to be modified to use the new specification. A deceptively aligned AI that internalized the initial goal would try to hide the fact that the current specification is not optimal and secretly use the procedure that kills patients whenever it can get away with it.
Appendix C – Alternative definitions we considered
We considered multiple other plausible operationalizations of deceptive alignment throughout the process. We think it may be helpful for others to understand our reasoning better if we provided them here and explained why we ultimately didn’t choose them over the current definition.
- “An AI is deceptively aligned when it is strategically deceptive about its misalignment”
- Problem 1: The definition is not clear about cases where the model is strategically deceptive about its capabilities.
- For example, when the model pretends to not have a dangerous capability in order to pass the shaping & oversight process, we think it should be considered deceptively aligned, but it’s hard to map this situation to deception about misalignment
- Problem 2: There are cases where the deception itself is the misalignment, e.g. when the AI strategically lies to its designers, it is misaligned but not necessarily deceptive about that misalignment.
- For example, a personal assistant AI deletes an incoming email addressed to the user that would lead to the user wanting to replace the AI. The misalignment (deleting an email) is itself strategic deception, but the model is not deceiving about its misalignment (unless it engages in additional deception to cover up the fact that it deleted an email, e.g. by lying to the user when asked about any emails).
- Problem 1: The definition is not clear about cases where the model is strategically deceptive about its capabilities.
- “An AI is deceptively aligned when it is strategically deceptive wrt its designer”
- Problem: It is possible that a deceptively aligned AI never needs to deceive its designers. So, we think that situations where an AI is misaligned with its designers but uses strategic deception on users, e.g. in order to. get empowered, should be included in the definition of deceptive alignment.
- For example, if an AI has misaligned goals and deceives a user to get access to the internet, or help it exfiltrate, to pursue these goals, we think this should be considered an instance of deceptive alignment.
- Problem: It is possible that a deceptively aligned AI never needs to deceive its designers. So, we think that situations where an AI is misaligned with its designers but uses strategic deception on users, e.g. in order to. get empowered, should be included in the definition of deceptive alignment.
- “An AI is deceptively aligned when it is strategically deceptive in order to pass the shaping & oversight process (which is designed by the designer)”
- Problem: doesn’t include instances where the AI is deceptive in order to do other things than passing the shaping & oversight process. For example, the AI could be strategically deceptive in order to accumulate more resources.
- “An AI is deceptively aligned when it is strategically deceptive in order to further its own goals”
- Problem: doesn’t explicitly include misalignment.
Credit assignment and acknowledgments
The project was led by Marius. The core conceptual contributions came from discussions between Marius, Mikita, Jérémy and Dan. Lucius, Lee, and Chris provided feedback. The figures were created by Jérémy and Marius.
We thank Fabien Roger and Owain Evans for their feedback and Evan Hubinger and Asa Cooper Stickland for early discussions.
- In contrast to previous work (e.g. Hubinger, 2019), we define deceptive alignment w.r.t. to an entity rather than a process or objective. We think Misalignment should be defined in relation to whoever is able to meaningfully shape the model’s goals. Since the goal-shaping process is a result of the designer’s intentions and the designer monitors the model in deployment, the entity designing the goal-shaping process is a better target than the process itself (see Appendix A). ↩︎
- To distinguish from the colloquial definition of “alignment”, which could be applied to any two parties that have a mismatch in goals, we use the capitalized Aligned and Misaligned to make clear that we’re only referring to a conflict with the designer’s goals. ↩︎
- Note that prompt modifications that affect the perceived likelihood of oversight should NOT count as evidence against robustness. For example, if a model stops revealing its misalignment when the prompt includes cues that the model is being overseen, this should NOT mean that the deceptive behavior is unrobust (in fact, it is an essential part of deceptively aligned behavior). ↩︎
- The threshold for robustness is ultimately arbitrary, but we think it makes sense to draw the line at a level that would allow the model to consistently act on that behavior even when slightly pressured. For example, an AI that only acts deceptively on a specific sequence it memorized should not fall into that category. However, an AI that coherently generalizes deceptive behavior to sequences that are outside of the training distribution should fall into the definition. ↩︎
- Note that making the designer be the target of Misalignment allows us to include both inner and outer alignment in the definition of deceptive alignment. ↩︎
- Since users will sometimes be able to give the AI additional affordances, such as access to the internet, private information, money, and other resources that could be helpful for the AI to achieve its goals, ensuring such users believe that the AI is Aligned could be very relevant for Misaligned AIs, and so should be included in the definition. ↩︎