Apollo’s product vision
Summary
- We’re building tools that make it easier to secure frontier AI agents.
- We’re starting with AI agent monitoring, specifically coding agents.
- If you have a lot of agent logs and are interested in partnering with us to analyze them, please reach out.
High-level vision
We build products to increase the safety of increasingly powerful and autonomous AI agents. Our safety tools are always designed for the latest frontier systems on the path to AGI.

As AI agent capabilities increase, they will become capable of increasingly complex tasks. Currently, we’re already seeing significant improvements in coding agents and early signs of life for narrow research agents, such as Deep Research. Soon, we expect that agents will be general and reliable enough that they can be used as a drop-in remote worker for many white-collar jobs. Eventually, they will likely be able to do entirely novel kinds of research, such as finding new cures to diseases or drastically speeding up AI development itself.
All of these agents have many safety & security failure modes. They will have read and write access to computers, sensitive information, and the internet. We intend to build tools for developers and deployers of AI agents to make their systems more safe and secure.
Institutions for AI systems
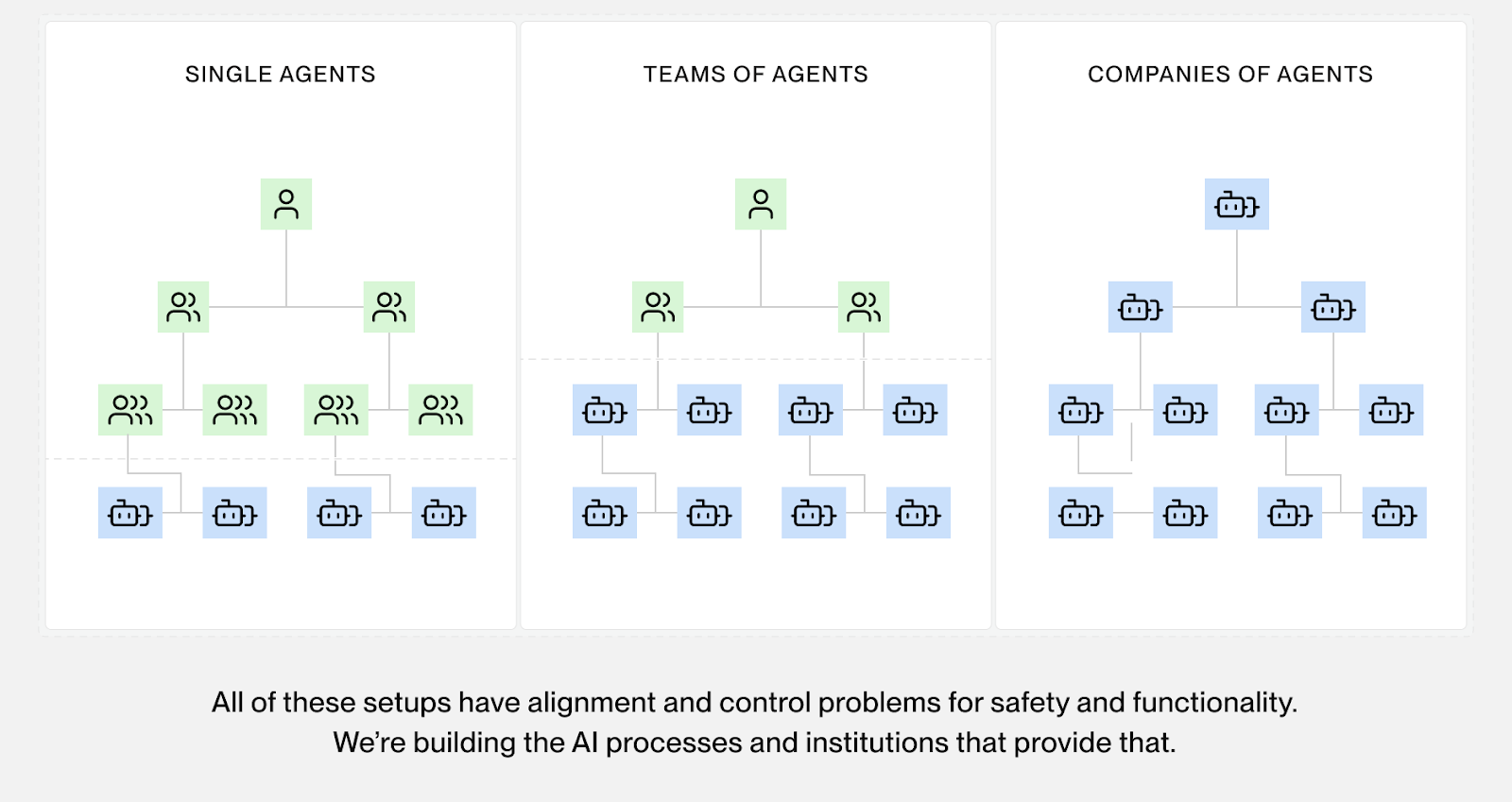
As AI agent capabilities increase, failure modes become more complex.
First, we need to secure single AI agents, such as coding agents like Claude Code, Codex, or Cursor. For this, we need to ensure that these agents perform exactly as intended during hour-long deployments, while also keeping track of numerous implicit or explicit constraints. We think monitoring (both offline and real-time) and real-time interventions are the obvious answers to that problem, and we’re currently building out a tech stack for that.
Second, we need to secure multi-agent teams, such as research teams of specialized agents collaborating to solve complex scientific questions. These agents will have individual objectives and incentives, and they will require active coordination to prevent safety failures. For example, if multiple agents disagree on the strategy, they could vote, or one agent could decide to sabotage the project, resulting in a bad outcome. While current AI systems are not yet at this level, we expect future AI systems to create a whole new range of safety failures related to agent coordination.
Third, we need to secure AI agent companies, e.g., complex structures of agents working together to achieve an overall goal. These AI agent companies likely have hierarchies and incentive structures. If these incentives are set incorrectly, e.g., where hiding failures is accidentally incentivized, the agents will learn to be deceptive. Therefore, they need ways to correctly shape and update incentives, resolve disagreements, and correct mistakes.
There are alignment and control problems at all layers of the agent stack that need to be addressed to create reliable and safe outcomes. Humans have designed and improved institutions for these failures for hundreds of years (e.g., Democracy, Governments, Justice systems, Police, Corporate Governance, …). Given the current pace of AI development, it is possible that similar institutions may need to be designed and built within a decade. Our long-term vision for the product team is to build such institutions at all layers of the future AI agent stack.
AI agent monitoring
We’re building a stack for AI agent monitoring. Our goal is to build a powerful log-analysis engine that can ingest millions of logs and return exactly the ones that are most relevant for any particular failure mode, ranked by importance. We’re interested in running both offline and real-time monitors for detailed analysis and immediate control.
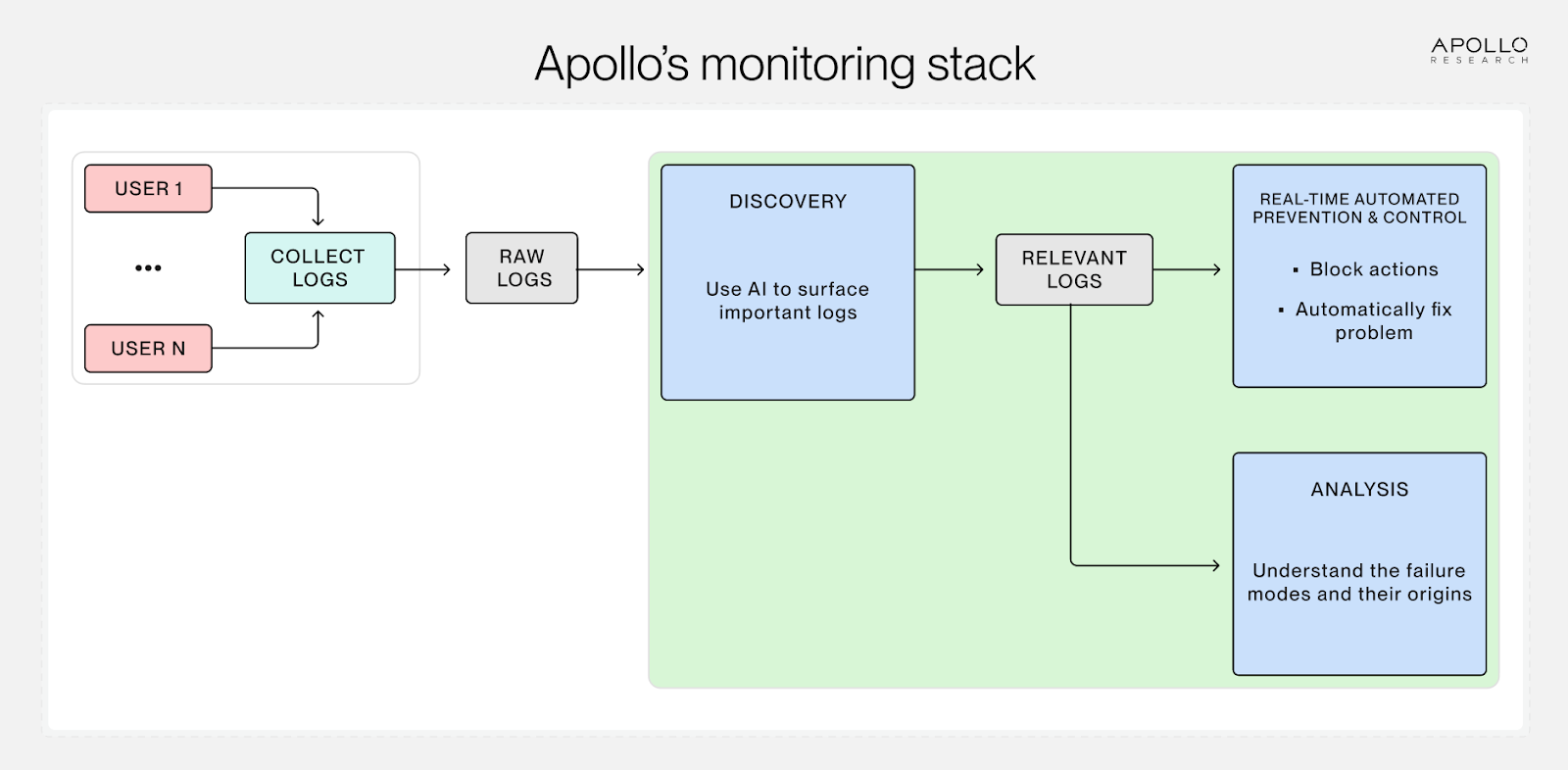
Call for partnerships: We have an MVP of this pipeline up and running. We’re interested in partnering with other organizations. If you have a lot of AI agent logs and would like to analyze them automatically at scale, please reach out.